
結構重いOpenCVのinpaintを改善できないか?
WoLNamesBlackedOutは、いつも通り鳴かず飛ばずの人気で。
Inpaintは透明風の処理で悪くないと感じているのですが、如何せん処理が重い!
また周辺から埋めるのでのっぺりとした感じになりがちなのもちょっと・・・
OpenCVのinpaintを使ってるけど、もしかしてONNX推論すれば、より高速に、しかも綺麗にできたりしない?
DeepFillv2やLAMA-regularが良いらしい?
ONNX-DirectMLで推論できるinpaintモデルとして、deepfillv2やLAMA-regularが良さそう?
deepfillv2はちょっとモヤモヤが気になったので、LAMA-regularを試してみた!
環境づくりが結構大変だったので、そっとQiitaに投稿しておいた。
ファインチューニングしようかと思ってたけど、事前学習済みモデルで試してみたのが下の画像。
左から、元の画像、マスク、処理した画像、元の画像+マスク+処理した画像。
そんなにおかしくなさそうで、結構自然に見えるので、とりあえず事前学習済みモデルで実装してみることに。

とりあえずWoLNamesBlackedOutに実装してみた。
ONNXには毎回手を焼かされるので、なかなか手が進まなかったけど、でも大きく改善するかも!という気持ちで重い腰を上げて頑張って実装!
まずは静止画に実装して動作確認。
一応動き出したかな?
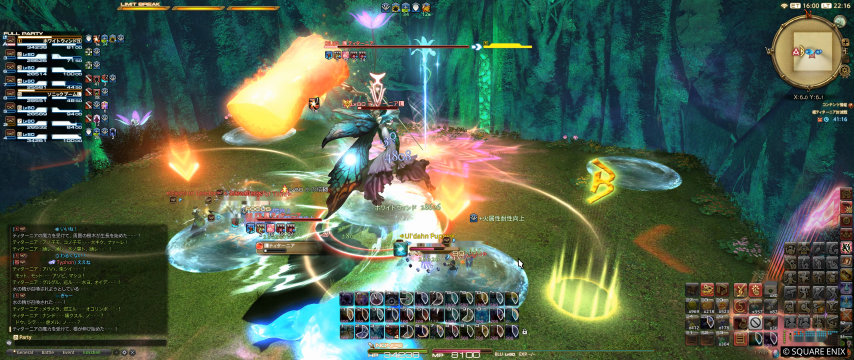
これがopencvのinpaintで、
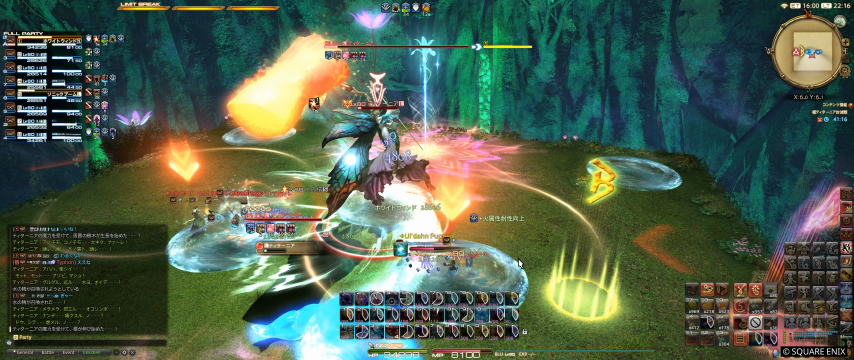
これがLAMA-regularのinpaint
こち亀のように、全部同じじゃないですか!って言われそうだけど、
opencvのinpaintでは、周辺から埋めてる関係でパーティリストで白いHPバーが縦方向に伸びてて。
LAMA-regularのinpaintではそういうのはないけど、周辺情報を参考に埋めてる関係から、せっかく消した文字の場所に文字っぽいゴミが出てたり。
うーん・・・これはどうなんだろう・・・?
どっちがいいのかな?
とりあえず動画の処理の方にも仮実装して、処理速度を評価してみるかな!
で、動画の方にも反映してみた!
処理速度は8FPS!おそーい!超遅い!
ONNX-DirectMLでyolo26物体検出をして、そこにONNX-DirectMLでLAMA-regular inpaintで動かしてみたのですが、8FPS!
この前の物体追跡でも遅かったんですが、こっちの推論、あっちの推論と、いろんな推論がいろいろ動くとどうしても遅くなるのかも?
うまくやらないとFPSでないのかもしれない。
どちらもTensorRT-RTXで動かす、という可能性も残してはいたのですが、DirectMLで8FPSだとTensorRT-RTXでもあまり大きな期待はできなさそうなのと、見た目にゴミが出てしまうのも気になって、LAMA-regularの採用はあきらめました。ざんねん!
せっかくなので、と記念に頑張って出力した動画が上のものになります。
こうみると、opencvのinpaintの方が私の使い方にはマッチしているのかもね。