
ONNXRUNTIMEでどうして1つ検出できない問題がクリア!
おらやったどー!
全部検出できた画像© SQUARE ENIX がこちら!わーいわーい!
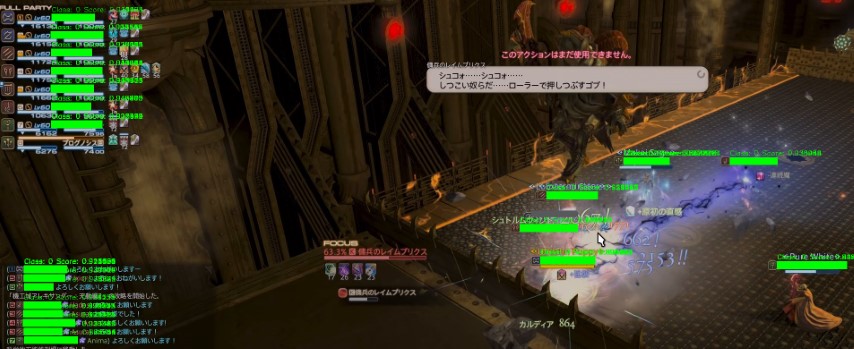
昨年末からナンデダロー?ナンデダロー?ってずっと悩んでいたのですが、解決しました!
よかった!
参考にさせて頂いた記事とコードのちょっとした誤記だったのですが、わたしが根本的に仕組みを理解せずに利用させて頂いていたので、なかなか原因にたどり着けませんでしたー。
元は同じONNXモデルとなるTensorRTでの推論に参考とさせていただいたコードでは、全て検出できていたので、また更に悩むことに・・・。
でも、いろんなコードを見比べたり調査することで仕組みやコードがどのような形で解決しようとしてるかとかがよくわかって、ある意味いい機会となって勉強になりました!
調べて理解するほどに、ここは合ってそう、ここも合ってそう・・・と間違っていそうなところがなくて、これまた悩みましたー。
いやー、ほんと良かった!迷宮入りするかと思った。
YOLOv8、ONNXRUNTIME、C++、TensorRTの適用について
私はPythonではUltralytics YOLOv8を利用して物体検出モデルを作ったのですが、C++、ONNXRUNTIMEでの推論で参考とさせていただいた記事はこちらです。1件検出できない問題はありましたが(いまは記事修正されてます)それ以外は仕組みを大きく変えることなくほぼそのまま利用できる状態のコードでとても助かりました!ありがたやー
TensorRTはこちら。こちらの記事の中央あたりにyolov8の出力テンソルのデータ形状や後処理の順序が図示されていて、出力テンソルや後処理について一気に理解が進みました。またコードもほぼそのまま利用できるもので、ほぼそのまま利用させて頂こうと思っています。ありがたやー
https://cyberyang.com/inference/34.html
アプリはTensorRTか、DirectMLの2択にしようかな
CUDAが思いのほか遅かったので、GeforceではTensorRTの利用を推奨する形で進めることとして、TensorRTを利用できない場合はDirectX12を利用するDirectMLでのONNXRUNTIME推論にしようかな?と考えました。
Geforce1080などの人はCUDA使いたいかなー?とは思ったものの、TensorRTとDirectMLだけを対象とすることでアプリを分けずに1つだけにすることができそうなのが大きいと感じたためです。
同じONNXRUNTIMEを使うものなので、CUDAからDirectMLに変更するのはそこまで大きな変更ではなかったので、早速試してみました。
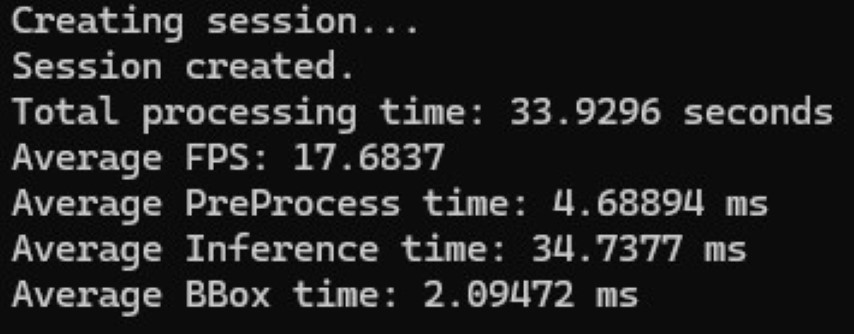
・・・なんかDirectMLの方がCUDAより速いね?
なんでだろ?CUDAはオプションとか触ってなかったから??かな??
ま、たくさんの人にGPUの恩恵を受けられるし、結果オーライかな!
物体検出についてはだいたい目途がついたし、次はいよいよUIづくりかな!