ONNX-CUDAが思ってたより遅くてガックリきてました・・・
結構ガックリきてました・・・
コピペが多いとは言え、VisualC++でONNXをCUDAで推論できるようになって、FFmpegで動画の入出力をできるようにして、これでいよいよUI作成編に突入かな!と思ってたのに・・・
まさかのPythonのEXE化よりも遅いなんて・・・
確かにPythonはtorch-tensorrtで高速化されているしなー
NuGetしたonnxruntimeにはtensorrtのExecution Providerもあったので、ONNXをtensorrtで実行できるようにできたらいいのかなー?
そんなことを考えながらアレコレと検索していたところ、良く考えたらONNXにこだわらずにTensorRTで動かせばいいじゃん!みたいな!
TensorRTを試してみる!
TensorRTのランタイムには、ヘッダファイルやライブラリ、DLLの他に、`trtexec.exe`という実行ファイルが準備されていたりする。
この実行ファイルは、ONNXファイルをTensorRTファイルのengineに変換してくれたり、変換したTensorRTファイルを実行してみてどれくらいのレスポンスがでるか実演してくれたりする!
早速やってみた!
基本的には次のコマンドで試せる。
trtexec --onnx=my_yolov8m.onnxうちのはONNXが(無駄に)dynamicになっていて、そのままでは動かないので入力テンソルの形状を指示してあげる。
trtexec --onnx=my_yolov8m.onnx --shapes=images:1x3x1280x1280`trtexec -h`でオプション一覧が出るので困ったらそれを見たらok!
動き出した!
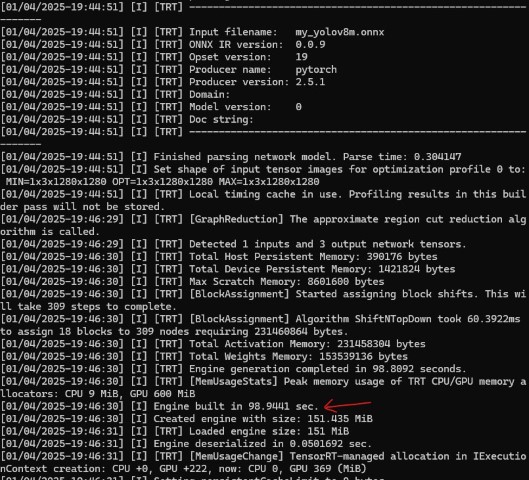
ONNXからTensorRTには99秒かかったみたい。
最初に一度変換したら、基本的にそれ以降はずっと使いまわせるから、まぁ許せる範囲かな?
作ろうとしているアプリの対象となる動画だと10分とか15分とかあるだろうし、それが少しでも早く処理できるなら初回の1分半は全然許せる!
果たして結果は・・・
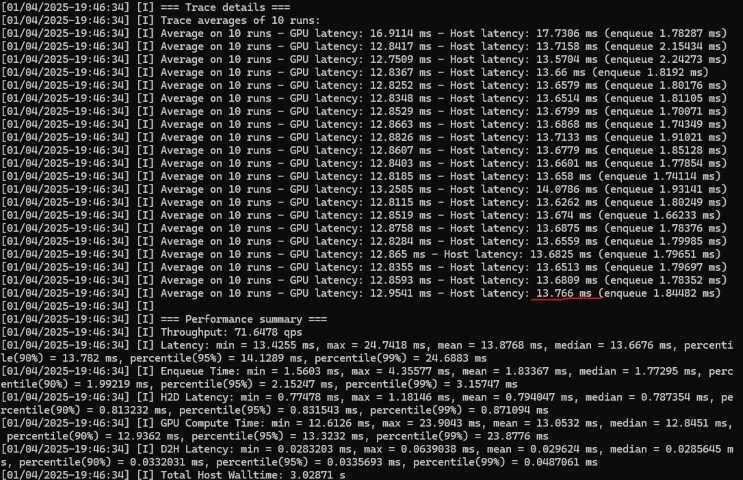
13ms!!え?まじで??
昨日のONNX-CUDAはいくつだっけ??45ms?
すげー!TensorRTすげー!Nvidiaは神!
TensorRTはまだ変身を残しているんですよ・・・
TensorRTにはまだFP16という変身を残してるよ?やっちゃう?FP16もやっちゃう??
コマンドはこんな感じ
trtexec --onnx=my_yolov8m.onnx --shapes=images:1x3x1280x1280 --fp16
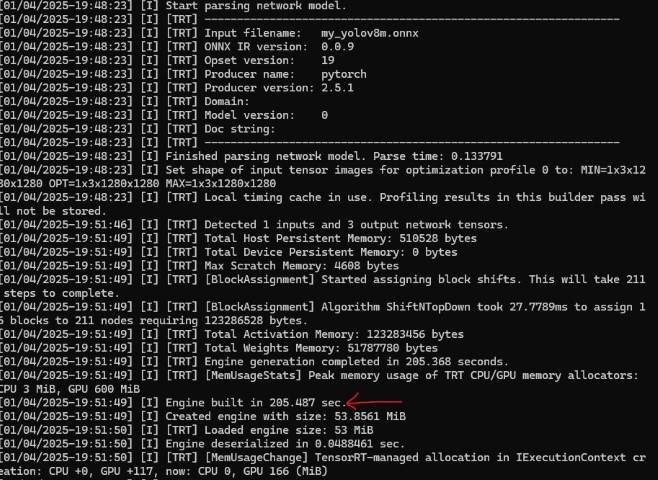
変換には205秒かかった。FP16とFP32の両方を作るから、かな?
3分くらい?まぁ初回だけだし、許そう!許して!
はてさて結果は・・・
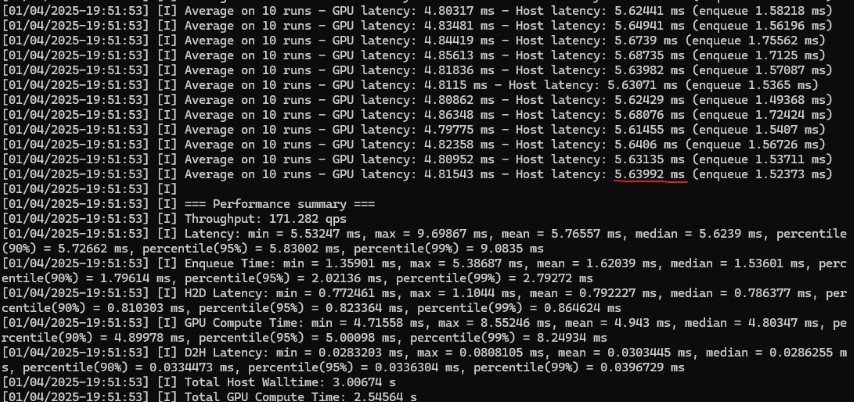
5.6ms!!
すげー!!!TensorRTすげー!!
仮に5.6msがそのままアプリに適用できたとして、60FPSの動画を処理した時のFPSは1000/5.6=178FPS!!
3倍速!!
NVIDIAは神!これはNVIDIA株の買い増し待ったなし!!
これならTensorRTで行かざるを得ない!!
行かざるを得ない!
TensorRTは、各GPUに特化した推論を行うために、各クライアントPC毎に変換を実施する必要があるとは言え、この処理スピードは感動もの!
リアルタイムに黒塗りも夢ではなくなる処理速度だと思う!
サンプルコードを実行してみると、結果の検出画像表示が速い!
というわけで、
Nvidia GeforceはTensorRTで推論する方向でアプリ開発頑張る!
AMD RADEONはONNX-DirectML版での対応かな?8FPSくらい?ちょっと使い物にならないかなー?
ROCm対応すればもしかしたら速いのかもしれないけど、RADEON持ってないしなー
TensorRT目的で、やすいGeforce買うのもいいんじゃないかなー?
じゃあRADEON買えよって言われたら、まぁそうですね・・・ごめんなさい。