
アプリの物体検出精度を少しあげたかった!
画面を縮小したことで処理速度も改善され、あとはもうちょっと物体検出精度をあげて、チラチラ認識を減らしたい!
そこで私はUltralyticsのDiscordに参加し、質問をしてみた!
叱られた。
まぁ変なことしてるよ!って指摘されたっていうだけなんですが。
その時TensorRTへエクスポートしたら早くなるよ!って言われて。
でも指摘された通りコードを直すと、かなりいい感じに動くようになったので、やっぱりコードが変だったせいで実はTensorRTももしかしてうまく動いちゃう??
というわけでTensorRTエクスポートを再びやってみた!
結果は!
pyinstallerにてEXEにした状態で、
pytorch(.pt):22FPS (現状)
TensorRT(.engine):20FPS
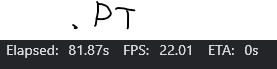

なんでだろう?
- 実はPythonで直に動かしている時は、pytorch(.pt)が25FPS、TensorRT(.engine)が28FPSだった。
CPU側の負荷が処理速度のネックになっている印象で、CPUに余裕があればもう少し早くなるんじゃないか?とも思っていた。 - でも、pyinstallerでWindows exeにすると、上記のように22FPSと19FPSに。
- pyinstallerによるオーバーヘッドが大きいのかなー?
- torch-tensorrtもそこそこ頑張ってる、TensorRT側はオーバーヘッドが大きい、みたいな感じ?
- もし配信対応やOBSプラグインなどを目指す場合には、C++などちゃんとした開発言語で作らないといけないと思ったようなレスポンス出ないだろうなー。誰か作ってくれないかなー
torchscriptも試してみた
torchscriptもエクスポートして、試してみました。
pyinstallerにてEXEにした状態で、18FPSくらいでした。
pythonでも20FPS程度でした。
結論的には、
- python上で実行するならTensorRTにエクスポートするとCPU側がネック工程になり、28FPS程度に上昇。
- pyinstallerでのexeで実行するなら、pytorchの.ptがもっとも性能がよく22FPS
という感じのようです。